Methods
Land Use and Land Cover Classes
The Brazilian National Inventory of Greenhouse Gases Emissions (Inventory) defines a set of land use and land cover classes to be used to estimate the GHG emissions from the AFOLU (Agriculture, Forest and Other Land Uses) sector. However, some of these classes cannot reliably be identified in LANDSAT images, even with advanced machine learning methods. Therefore, the LUC-Brazil project has defined a set of classes relevant to the Inventory shown in Table 1. These classes will later be converted conversion to the Inventory LUCC classes.
| IPCC Classes | LUC BRAZIL Amazonia | Description |
|---|---|---|
| Forest | Primary Forest | Natural forest as defined by PRODES |
| Secondary Vegetation | Regenerated or restored natural forest post-clear cuts | |
| Silviculture | Planted forest with exotic species | |
| Cropland | Annual Agriculture | One-cycle and two-cycle agriculture, mostly soy with corn or soy with cotton |
| Semi-Perennial Agriculture | Sugarcane farms | |
| Perennial Agriculture | Cocoa and Palm Oil large-scale plantations | |
| Grassland | Pasture | Cattle-raising areas |
| Natural Non-Forest Vegetation | Cerrado areas inside Amazon biome | |
| Wetland | Water Bodies | Rivers and Lakes |
| Wetlands | Flooded area | |
| Settlements | Urban Areas | Yearly or seasonally flooded areas with vegetation |
| Others | Mining | Large and medium-sized open-air mineral extraction |
| Deforestation | Areas cleared in the current year |
Processing Overview
The classification system operates through distinct stages, each handling a specific aspect of the data transformation pipeline from raw satellite imagery to final classified masks.
- Datacube Generation: Raw Landsat data from multiple sources is regularized into consistent 30m resolution time series for each year.
- Sample Selection and Analysis : The project uses a large set of samples containing ground truth information for selected location, described in the data section. These samples are analyzed using: (a) visual interpretation of high-resolution images; (b) quality control methods including self-organized maps. If required, the training set is rebalanced to account for underrepresented classes.
- Model Training; Using the cleaned set of samples to derive a machine learning model for classification based on the Random Forest algorithm.
- Classification: The Random Forest models classify regularized datacubes into initial land cover categories.
- Temporal Processing and Year-Specific Refinement: Multi-year rules refine classifications by analyzing temporal patterns. Individual annual masks undergo sequential reclassification rules.
Stage 1: Datacube Generation
The pipeline begins by ingesting raw Landsat imagery from two distinct sources, each optimized for different temporal periods. This stage produces regularized datacubes with consistent 30m spatial resolution and regular temporal intervals. These sources are described in the “Data” section.
Machine learning and deep learning (ML/DL) classification algorithms require the input data to be consistent. The dimensionality of the data used for training the model has to be the same as that of the data to be classified. There should be no gaps and no missing values. Thus, to use machine learning algorithms for remote sensing data, image collections should be converted to regular data cubes. The LUC-Brasil project uses regular data cubes produced by GLAD (Global Land Analysis & Discovery) from the University of Maryland for the period 2000-2015 and by the Brazil Data Cube for the period 2015-2025. The reason to use the GLAD data before 2015 is the limitations of the Landsat-5 and Landsat-7 satellites which were available in this period. The team at University of Maryland invested in reducing the radiometric and geometric problems of these satellites. To do so, they chose a two-month interval for their time series. By contrast, images in the Brazil Data Cube from 2015 onwards rely primarily on the Landsat-8 satellite, which has a much better geometrical and radiometric quality than the previous Landsat satellites. For this reason, images from 2015 onwards have a one-month temporal interval. This multi-source temporal integration enables robust classification across the 25-year analysis period (2000-2024) despite varying data availability.
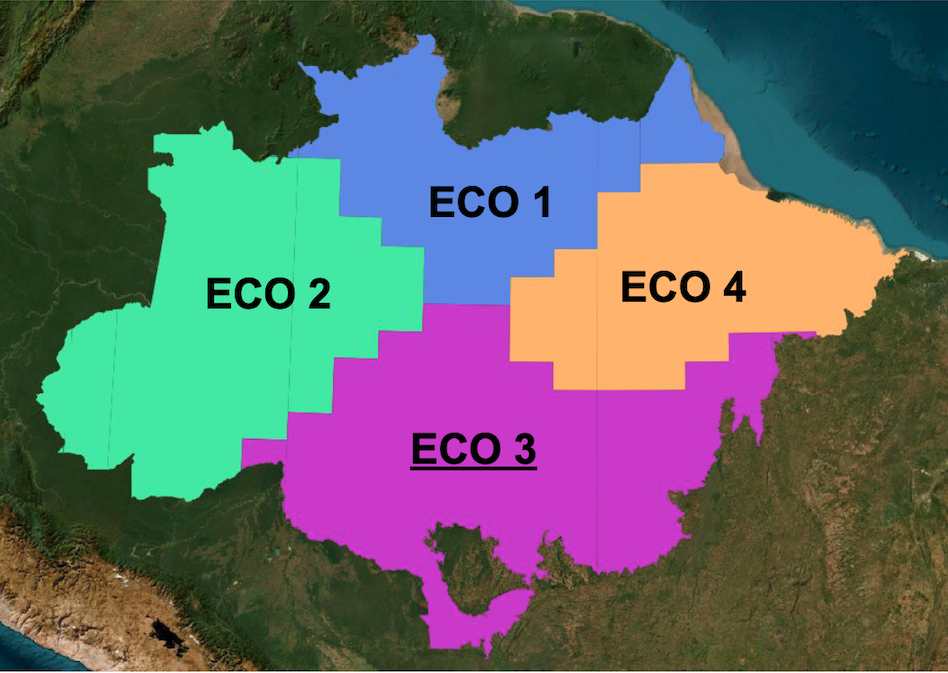
The Brazilian Amazon biome was divided into four ecoregions, according to their intrinsic natural variability and different patterns of human occupation (see Figure 1). Ecoregion 1 covers the Amapá and Roraima states, and parts of the Pará and Amazonas states in the North side of the Negro, Solimoes and Amazonas rivers. This regions is largely preserved, but has hot-spots of deforestation in Roraima. It also has a sizeable non-forest area in Roraima. Ecoregion 2 is the area bound by the Madeira and Negro rivers. It is mostly composed of native forest, except for the State of Acre and the recent expansion of deforestation along the Transamazonica road. Ecoregion 3 is the most affected by deforestation since the 1990s, which large areas of clearings used for pasture and agriculture. This is the area of Amazonia that has registered the largest deforestation rates measured by INPE’s PRODES system. Ecoregion 4 includes area of long-term human occupation in the Pará State (Zona Bragantina) where there is significant presence of planted forests and perennial agriculture (e.g., cocoa and oil palm). It is also the region of contact with the Cerrado areas in the State of Maranhão.
Stage 2: Sample Selection and Analysis
The team analyzed the ground truth samples available described in the “Data” section of this document using visual interpretation, exploratory data analysis, and quality assurance using self-organized maps. The visual analysis step consists of comparing the labelled samples from different sources with image backgrounds which can be either high-resolution images (e.g., Planet) or mid-resolution (e.g., Sentinel-2).
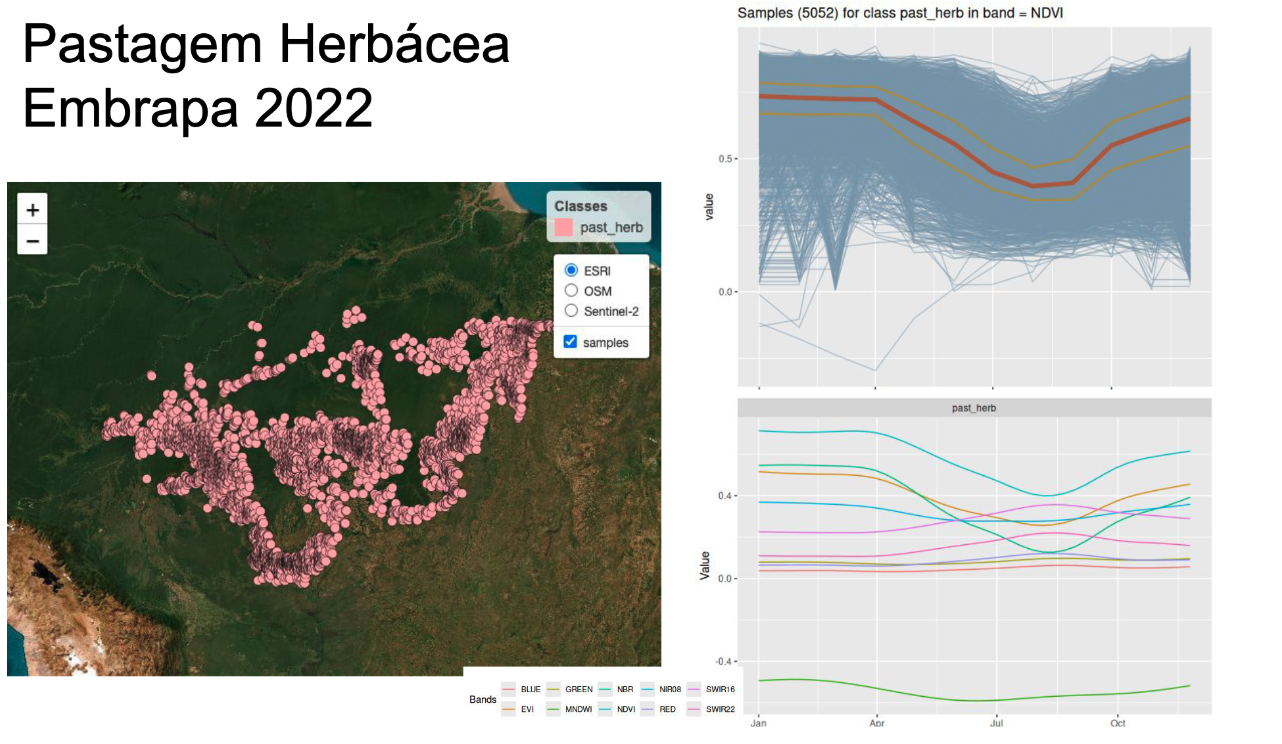
Exploratory data analysis refers to inspecting the samples time series and also finding patterns in the data, as shown in Figure 2. In the left side, one can see the spatial location of the samples for herbaceous pasture provided by EMBRAPA. The graph on the top right shows all of the associated time series for the NDVI band, together with their median (shown in brown) and the first and third quartile ranges (shown in yellow). The graph on the lower right shows a plots that captures the temporal variability of herbaceous pasture samples in the different bands. We use a generalized additive model (GAM) to obtain a single time series based on statistical approximation.
The sample quality assurance part uses self-organizing maps (SOM), a clustering method where high-dimensional data is mapped into a two-dimensional map, The input data for quality assessment is a set of training samples, which are high-dimensional data; for example, a time series with 25 instances of 4 spectral bands has 100 dimensions. When projecting a high-dimensional dataset into a 2D SOM map. Each time series will be mapped to one of the neurons. Since the number of neurons is smaller than the number of classes, each neuron will be associated with many time series. The resulting 2D map will be a set of clusters. The neighbors of each neuron of a SOM map provide information on intraclass and interclass variability, which is used to detect noisy samples. The methodology of using SOM for sample quality assessment is discussed in detail in the reference paper [1].
Based on the SOM analysis, we selected two sample collections, one for the 2000-2014 period, and other for the 2015-2024 period, which are summarized below. We first present the training set for 2000-2014.
SITS - satellite image time series analysis.Loaded sits v1.5.5.
See ?sits for help, citation("sits") for use in publication.
Documentation avaliable in https://e-sensing.github.io/sitsbook/# retrieve the samples for the 2000-2015 period
samples_amz_2010 <- readRDS("./etc/samples_amz_2010.rds")
summary(samples_amz_2010)# A tibble: 11 × 3
label count prop
<chr> <int> <dbl>
1 Annual Agriculture 1160 0.0927
2 Forest 1162 0.0929
3 Herbaceous Pasture 2900 0.232
4 Mountainside_Forest 127 0.0102
5 Riparian_Forest 865 0.0691
6 Seasonally_Flooded 731 0.0584
7 Secondary Vegetation 2186 0.175
8 Semi-Perennial Agriculture 757 0.0605
9 Shrubby Pasture 584 0.0467
10 Silviculture 1856 0.148
11 Wetlands 184 0.0147Some of the classes used in the training sample set are not included in the final LUC-Brazil classes. These include classes such as “Riparian_Forest” and “Seasonally_Flooded”. These classes are useful to discriminate between different types of natural forests and are later aggregated into the “Forest” class. Other classes produced by LUC-Brazil such as “Perennial Vegetation” are not present in the data set and are added later using reclassification rules. Extensive testing by the team shows that this class is not detectable using Landsat-5 and Landsat-7 images.
For the period 2015-2020, the distribution of the training set is shown below.
# retrieve the samples for the 2000-2015 period
samples_amz_2020 <- readRDS("./etc/samples_amz_2010.rds")
summary(samples_amz_2020)# A tibble: 11 × 3
label count prop
<chr> <int> <dbl>
1 Annual Agriculture 1160 0.0927
2 Forest 1162 0.0929
3 Herbaceous Pasture 2900 0.232
4 Mountainside_Forest 127 0.0102
5 Riparian_Forest 865 0.0691
6 Seasonally_Flooded 731 0.0584
7 Secondary Vegetation 2186 0.175
8 Semi-Perennial Agriculture 757 0.0605
9 Shrubby Pasture 584 0.0467
10 Silviculture 1856 0.148
11 Wetlands 184 0.0147Stage 3: Model Training
After experimenting with the different algorithms available in `sits, we chose the RandomForest method, which provides a reliable performance in the case of noisy data such as the images from Landsat-5 and Landsat-7 satellite. We performed a 5-fold validation of both models and present thre results below.
The confusion matrix and the metrics for the 2000-2014 model are shown below.
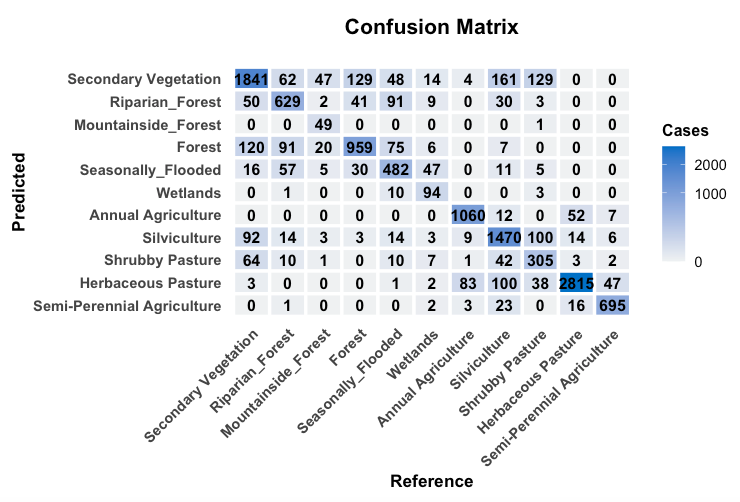
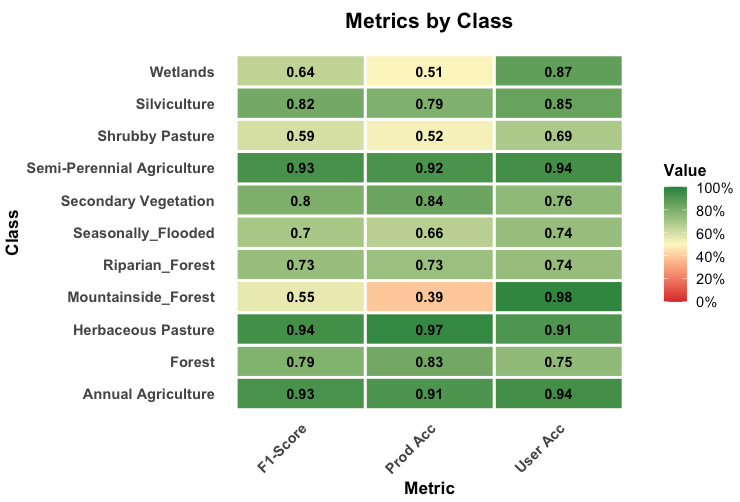
The results of the validation show a good degree of discrimination for the classes “Annual_Agriculture”, “Semi-Perennial Agriculture”, and “Herbaceous Pasture”. The natural forest classes (“Forest”, “Mountainside_Forest”, “Riparian_Forest” and “Seasonally_Flooded”) show a reasonable degree of internal confusion, which is not a big problem, since they will later aggreggated into a single class (“Forest”). The confusion between “Secondary_Vegetation” and “Forest” is to be expected; this confusion is solved using the PRODES maps.
Overall, the main problem is the distinction between the “Shrubby Pasture”, “Secondary Vegetation” and “Silviculture” classes. While the TerraClass maps provide a good basis for improving the classification of “Semi=Perennial Agriculture” and “Silviculture” classes, the main problem remains in the distinction between “Shrubby Pasture” and “Secondary Vegetation”. Indeed, these classes are hard to separate even in higher-resolution images.
The confusion matrix and the metrics for the 2015-2024 model are shown below.
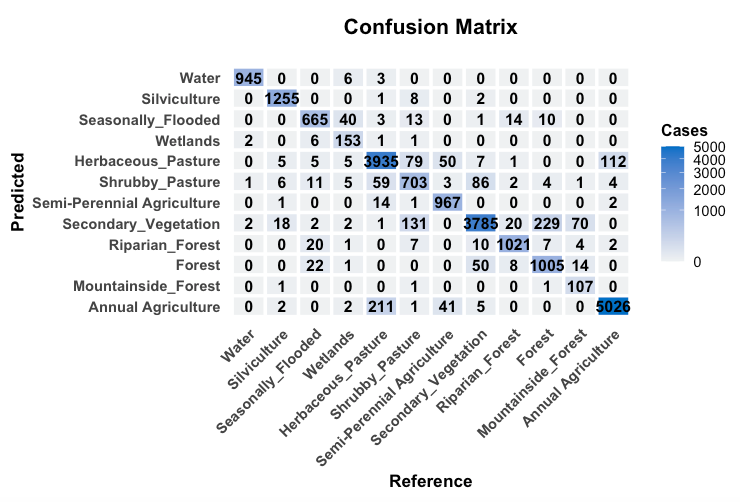
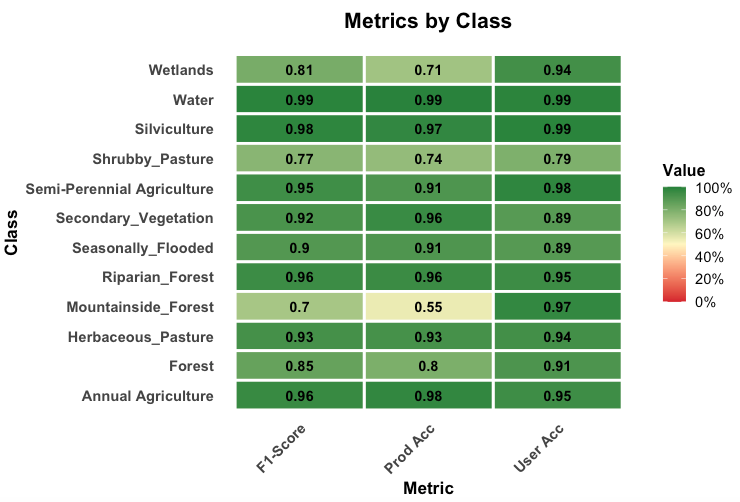
The results show that the 2014-2024 model discriminates the classes better than the 2000-2014 one. This outcome is expected due to the better quality of the Landsat-8 images. Compared to the 2000-2014 model, the “Silviculture” class is better defined, and the distinction between “Secondary Vegetation” and “Herbaceous Pasture” improves. The same remarks made earlier about the natural classes apply also in this case.
Stage 4: Datacube Classification
The datacube classification is done on an yearly basis. For each year, each spatial location (pixel) of the data cubes is associated to a time series. Each time series is then classified by the machine learning model. The result is a classified map for each year. The classification process is described in the detail in the on-line book about the sits package.
Stage 5: Reclassification rules
After the annual classification maps have been produced, the LUC-Brazil team applies a series of reclassification rules, which are described in detail in the next section.
References
[1]
L. A. Santos, K. R. Ferreira, G. Camara, M. C. A. Picoli, and R. E. Simoes, “Quality control and class noise reduction of satellite image time series,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 177, pp. 75–88, 2021, doi: 10.1016/j.isprsjprs.2021.04.014.